 |
 |
 |
 |
| |
|
||||
Writing Device Drivers for LynxOS |
|||||
Kernel Threads and Priority Tracking
Kernel threads keep drivers from interfering with the real-time response of the overall system. LynxOS kernel threads are designed specifically to increase driver functionality while decreasing driver response time, task response time, and task completion time. This chapter covers the implementation of kernel threads within a device driver.
Device Drivers in LynxOS
Device drivers form an important part of any operating system, but even more so in a real-time operating system such as LynxOS. The impact of the device driver performance on overall system performance is considerable. Since it is imperative for the operating system to provide deterministic response time to real-world events, device drivers must be designed with determinism in mind.
Some of the important components of real-time response are described in the following sections.
Interrupt Latency
Interrupt latency is the time taken for the system to acknowledge a hardware interrupt. This time is measured from when the hardware raises an interrupt to when the system starts executing the first instruction of the interrupt routine (in the case of LynxOS, this routine is the interrupt dispatcher). This time is dependent on the interrupt hardware design of the system and the longest time interrupts are disabled in the kernel or device drivers.
Interrupt Dispatch Time
Interrupt dispatch time is the time taken for the system to recognize the interrupt and begin executing the first instruction of the interrupt handler. Included in this time is the latency of the LynxOS interrupt dispatcher (usually negligible).
Driver Response Time
The driver response time is the sum of the interrupt latency and the interrupt dispatch time. This is also known as the interrupt response time.
Task Response Time
The task response time is the time taken by the operating system to begin running the first instruction of an application task after an interrupt has been received that makes the application ready to run. This figure is the total of:
- The driver response time (including the delays imposed by additional interrupts)
- The longest preemption time
- The context switch time
- The scheduling time
- The system call return time
Only the driver response time and the preemption time are under the control of the device driver writer. The other times depend on the implementation of LynxOS on the platform for which the driver is being written.
Task Completion Time
The task completion time is the time taken for a task to complete execution, including the time to process all interrupts which may occur during the execution of the application task.
Real-Time Response
To improve the real-time response of any operating system, the most important parameters are the driver response time, task response time, and the task completion time. The time taken by the driver in the system can have a direct effect on the system's overall real-time response. A single breach of this convention can cause a high performance real-time system to miss a real-time deadline.
In a normal system, interrupts have a higher priority than any task. A task, regardless of its priority, is interrupted if an interrupt is pending (unless the interrupts have been disabled). The result could mean that a low priority interrupt could interrupt a task executing with real-time constraints.
A classic example of this would be a task collecting data for a real-time data acquisition system and being interrupted by a low priority printer interrupt. The task would not continue execution until the interrupt service routine had finished.
With kernel threads, delays of this sort are significantly reduced. Instead of the interrupt service routine servicing the interrupt, a kernel thread is used to perform the function previously performed by the interrupt routine. The interrupt service routine is now reduced to merely signalling a semaphore, which the kernel thread is waiting on.
Since the kernel thread is running at the application's priority (actually it is running at half a priority level higher), it is scheduled according to process priority and not hardware priority. This ensures that the interrupt service time is kept to a minimum and the task response time is kept short. A further result of this is that the task completion time is also reduced.
The use of kernel threads and priority tracking in LynxOS drivers are the cornerstone to guaranteeing deterministic real-time performance.
Kernel Threads
Kernel threads execute in the virtual memory context of the null process, which is process 0. However, kernel threads do not have any user code associated with them, so context switch times for kernel threads are quicker than for user threads. Like all other tasks in the system, kernel threads have a scheduling priority that the driver can change dynamically to implement priority tracking. They are scheduled with the SCHED_FIFO algorithm.
Creating Kernel Threads
A kernel thread is created once in the install or open entry point. The advantage of starting it in open is that, if the device is never opened, the driver doesn't use up kernel resources unnecessarily. However, as the thread is only created once, the open routine must check whether this is the first call to open. One thread is created for each interrupting device, which normally corresponds to a major device.
The following code fragment illustrates how a thread might be started from the install entry point:
The thread function specifies a C function to be executed by the thread. The structure of the thread code is discussed in the next section.
The second argument specifies the thread's stack size. This stack does not grow dynamically, so enough space must be allocated to hold all the thread's local variables.
As kernel threads are preemptive tasks, they have a scheduling priority, just like other user threads in the system, which determines the order of execution between tasks. The priorities of kernel threads are discussed more fully in the "Priority Tracking". It is usual to create the thread with a priority of one.
The thread name is an arbitrary character string which is printed in the name column by the ps T command. It will be truncated to PNMLEN characters (including NULL terminator). PNMLEN is currently 32; see the proc.h file.
The last two parameters allow arguments to be passed to the thread. In most cases, it is sufficient to pass the address of the statics structure, which normally contains all other information the thread might need for communication and synchronization with the rest of the driver.
Structure of a Kernel Thread
The structure of a kernel thread and the way in which it communicates with the rest of the driver depends largely on the way in which the particular device is used. For the purposes of illustration, two different driver designs are discussed.
- Exclusive access: Only one user task is allowed to use the device at a time. The exclusive access is often enforced in the open entry point.
- Multiple access: Multiple user tasks are permitted to have the device open and make requests.
Exclusive Access
If we consider synchronous transfers only, this type of driver will typically have the following structure:
- The top-half entry point (read/write) starts the data transfer on the device, then blocks, waiting for I/O completion.
- The interrupt handler signals the kernel thread when the I/O completes.
- The kernel thread consists of an infinite for loop, which does the following:
The statics structure contains a number of variables for communication between the thread and the other entry points. These would include synchronization semaphores, error status, transfer length, etc.
Top-Half Entry Point
The read/write entry point code is not any different from a driver that does not use kernel threads. It starts an operation on the device, then blocks on an event synchronization semaphore.
Interrupt Handler
Apart from any operations that may be necessary to acknowledge the hardware interrupt, the interrupt handler's only responsibility is to signal the kernel thread, informing it that there is some work to do:
Kernel Thread
The kernel thread waits on an event synchronization semaphore. When an interrupt occurs, the thread is woken up by the interrupt handler. It processes the interrupt, checking the device status for errors, and wakes up the user task that is waiting for I/O completion. For best system real-time performance, the kernel thread should re-enable interrupts from the device.
Multiple Access
In this type of design, any number of user tasks can open a device and make requests to the driver. But as most devices can only perform one operation at a time, requests from multiple tasks must be held in a queue.
In a system without kernel threads, the structure of such a driver is:
- The top-half routine starts the operation immediately if the device is idle, otherwise it enqueues the request. It then blocks, waiting for the request to be completed.
- The interrupt handler processes interrupts, does all I/O completion, wakes up the user task and then starts the next operation on the device immediately if there are queued requests.
The problem with this strategy is that it can lead to an overly long interrupt routine owing to the large amount of work done in the handler. Since interrupt handlers are not preemptive, this can have an adverse effect on system response times. When multiple requests are queued up, the next operation is started immediately after the previous one has finished. The result of this is that a heavily-used device can generate a series of interrupts in rapid succession until the request queue is emptied. Even if the requests were made by low priority tasks, the processing of these interrupts and requests will take priority over high priority tasks because it is done within the interrupt handler.
The use of kernel threads resolves these problems by off-loading the interrupt handler. A kernel thread is responsible for dequeuing and starting requests, handling I/O completion and waking up the user tasks. The next figure illustrates the overall design.
A data structure containing variables for event synchronization, error status, etc., is used to describe each request. The pending request queue and list of free request headers are part of the statics structure. The interrupt handler code is the same as in exclusive access design.
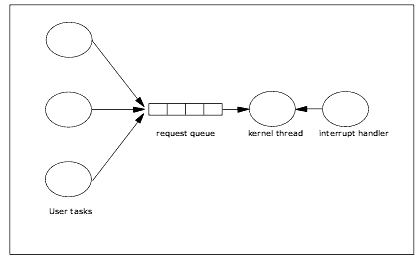
Top-Half Entry Point
Kernel Thread
Priority Tracking
The previous examples did not discuss the priority of the kernel thread. It was assumed to be set statically when the thread is created. There is a fundamental problem with using a static thread priority in that, whatever priority is chosen, there are always some conceivable situations where the order of task execution does not meet real-time requirements. The same is true of systems that implement separate scheduling classes for system- and user-level tasks.
The next figure shows two possible scenarios in a system using a static thread priority. In both scenarios, Task A uses a device that generates work for the kernel thread. Other tasks with different priorities exist in the system. These are represented by Task B.
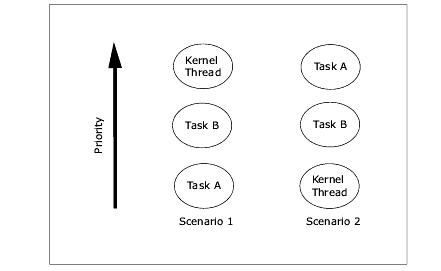
In the first scenario, Task B has a priority higher than Task A but lower than that of the kernel thread. The kernel thread will be scheduled before Task B, even though it is processing requests on behalf of a lower priority task. This is essentially the same situation that occurs when interrupt processing is done in the interrupt handler. In Scenario 2, the situation is reversed. The kernel thread is preempted by Task B resulting in Task A being delayed.
The only solution that can meet the requirements of a deterministic real-time system with bounded response times is to allow the kernel thread priority to dynamically follow the priorities of the tasks that are using a device.
User and Kernel Priorities
User applications can use 256 priority levels from 0-255. However, internally, the kernel uses 512 priority levels, 0-511. The user priority is converted to the internal representation simply by multiplying it by two, as illustrated in the figure below.
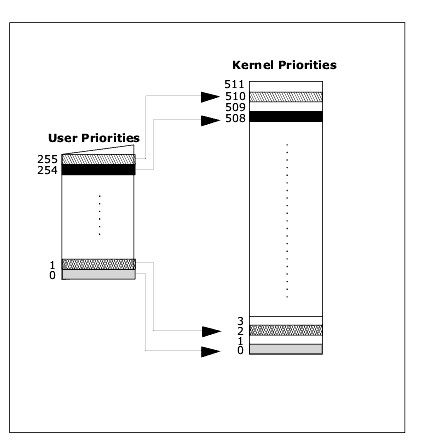
As can be seen, a user task will always have an even priority at the kernel level. This results in "empty," odd priority slots between the user priorities. These slots play an important role in priority tracking.
The following examples discuss exclusive and multiple access driver designs for illustrating priority tracking techniques.
Exclusive Access
Whenever a request is made to the driver, the top-half entry point must set the kernel thread priority to the priority of the user task.
The expression (uprio << 1) + 1 converts the user priority to a kernel-level priority. The thread priority is in fact set to the odd numbered kernel priority just above the priority of the user task. This ensures that the kernel thread executes before any tasks at the same or lower priority as the user task making the request but after any user tasks of higher priority, as shown in the figure below.
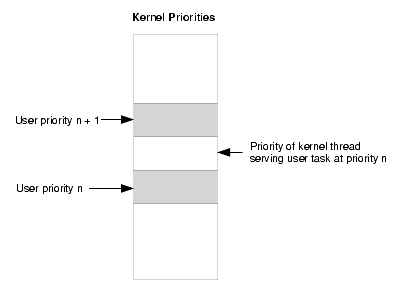
When the request has been completed, the thread resets its priority to its initial value.
Multiple Access
As previously discussed, the driver maintains a queue of pending requests from a number of user tasks. These tasks probably have different priorities. Therefore, the driver must ensure that the kernel thread is always running at the priority of the highest priority user task that has a request pending. If the requests are queued in priority order this ensures that the thread is always processing the highest priority request. The thread priority must be checked and adjusted at two places: whenever a new request is made, and whenever a request is completed.
How can the driver keep track of the priorities of all the user tasks that have outstanding requests? In order to do so, the driver must use a special data structure, struct priotrack, defined in st.h. Basically, the structure is a set of counters, one for each priority level. The value of each counter represents the number of outstanding requests at that priority. The values of the counters are incremented and decremented using the routines priot_add and priot_remove. The routine priot_max returns the highest priority in the set.
The use of these routines is illustrated in the following code examples.
Top-Half Entry Point
The top-half entry point must first use priot_add to add the new request to the set of tracked requests. The code then decides whether the kernel thread's priority must be adjusted. This will be necessary if the priority of the task making the new request is higher than the thread's current priority. A variable in the statics structure is used to track the kernel thread's current priority. The request header must also contain a field specifying the priority of the task making each request. This is used by the kernel thread.
* Do priority tracking. Add priority of new request
* to set. If priority of new request is higher than
* current thread priority, adjust thread priority.
Kernel Thread
When the kernel thread has finished processing a request, the priority of the completed request is removed from the set using priot_remove. The thread must then determine whether to change its priority, depending on the priorities of the remaining pending requests. The thread uses priot_max to determine the highest priority pending request.
Non-Atomic Requests
The previous examples implicitly assumed that requests made to the driver are handled atomically. That is to say, the device handles an arbitrary-size data transfer. This is not always the case. Many devices have a limit on the size of the transfer that can be made, in which case, the driver may have to divide the user data into smaller blocks. A good example is a driver for a serial device. A user task may request a transfer of many bytes, but the device can only transfer one byte at a time. The driver must split the request into multiple single byte requests.
From the point of view of priority tracking, a single task requesting an n byte transfer is equivalent to n tasks requesting single-byte transfers. Since each byte is handled as a separate transfer by the driver (each byte generates an interrupt), the priority tracking counters must count the number of bytes rather than the number of requests.
The functions priot_addn and priot_removen can be used to add and remove multiple requests to the set of tracked priorities. What is defined as a request depends on the way the driver is implemented. It will not always correspond on a one-to-one basis with a request at the application level.
Taking again the example of a driver for a serial device, a single request at the application level consists of a call to the driver to transfer a buffer of length n bytes. However, the driver will split the buffer into n single-byte transfers, each byte representing a request at the driver level. The top-half entry point would add n requests to the set of tracked priorities using priot_addn. As each byte is transferred, the kernel thread would remove each request priority using priot_remove.
The priority of the kernel thread would only be updated when all bytes have been transferred. It is very important that the priority tracking is based on requests as defined at the driver level, not the application level, in order for the priority tracking to work correctly.
Controlling Interrupts
One of the problems discussed concerning drivers that perform all interrupt processing in the interrupt handler is that in certain circumstances, a device can generate a series of interrupts in rapid succession. For many devices, the use of a kernel thread and priority tracking illustrated above resolves the problem.
Take, for example, a disk driver. The figure below represents a situation that can occur in a system without kernel threads. A lower priority task makes multiple requests to the driver. Before these requests are completed, a higher priority task begins execution. But the higher priority task is continually interrupted by the interrupt handler for the disk. Because of the amount of processing that can be done within the interrupt handler and because the number of requests queued up for the disk could have been very large, the response time of the system and execution time for the higher priority task is essentially unbounded.
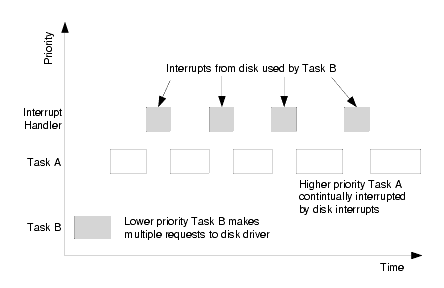
The next figure shows the same scenario using kernel threads. The important thing to note is that the higher priority task can only be interrupted once by the disk. The kernel thread is responsible for starting the next operation on the disk, but because the kernel thread's priority is based on Task B's priority, it will not run until the higher priority task has completed. In addition, the length of time during which Task A is interrupted by the interrupt handler is a small constant time, as the majority of the interrupt processing has been moved to the kernel thread.
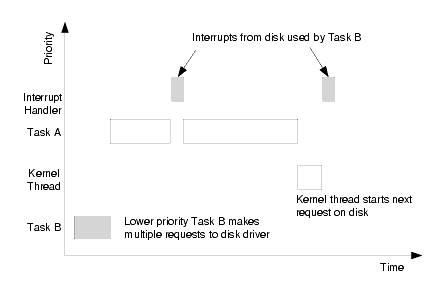
This scheme takes care of devices where requests are generated by lower priority user tasks. But what about devices where data is being sent from a remote system? The local operating system cannot control when or how many packets are received over an Ethernet connection. Or a user typing at a keyboard could generate multiple interrupts.
The solution to these situations is again based on the use of kernel threads. For such devices, the interrupt handler must disable further interrupts from the device. Interrupts are then re-enabled by the corresponding kernel thread. So again, a device can only generate a single interrupt until the thread has been scheduled to run.
Any higher priority tasks will execute to completion before the device-related thread and can be interrupted by a maximum of one interrupt from each device. The use of this technique requires that the device has the ability to store some small amount of incoming data locally during the time that its interrupt is disabled. This is not usually a problem for most devices.
|
LynuxWorks, Inc. 855 Branham Lane East San Jose, CA 95138 http://www.lynuxworks.com 1.800.255.5969 |
| |
|
|
|